
Strutture e campi funzione
Quando ci si avvicina alla programmazione C++ in modo sistematico, è quasi inevitabile imbattersi nel concetto di struct. Anche chi ha già una certa dimestichezza con le classi, prima o poi si chiede perché il linguaggio preveda un costrutto dal nome così breve, apparentemente molto simile a ciò che abbiamo imparato a chiamare “classe”. In realtà, le strutture (struct) nascono come retaggio di linguaggi più antichi, dove il raggruppamento di dati veniva affidato a un costrutto semplice, privo di gran parte della logica interna che oggi attribuiamo alle classi. Con il tempo, però, il C++ ha permesso di potenziare le struct, consentendo di includere funzioni membro, costruttori, distruttori e molto altro. È proprio qui che si fa strada il concetto di “campi funzione”, ossia la possibilità di inserire veri e propri metodi all’interno di quella che era, in origine, una semplice collezione di dati.
Questa lezione vuole essere un percorso di esplorazione su come le strutture in C++ possano essere utilizzate in modo moderno, con un linguaggio che, pur rimanendo informale, dia la sensazione di avere sotto mano uno strumento solido e ampiamente flessibile. Cercheremo di raccontare l’evoluzione delle struct, comprendendo come i campi funzione siano utili per organizzare il codice, incapsulando logicamente sia le informazioni sia le operazioni che le riguardano. L’idea è di fornire una panoramica che non sia un elenco di definizioni accademiche, ma piuttosto una narrazione estesa che accompagni il lettore attraverso curiosità, esempi pratici e riflessioni sullo stile di programmazione.
Strutture in C++ come base di partenza
Le strutture in C++ hanno una storia alle spalle che è strettamente legata al C, linguaggio dal quale ereditano la sintassi essenziale. In C, una struct non poteva contenere nulla che non fosse strettamente legato ai dati; si trattava di un modo per raggruppare variabili di tipi diversi sotto un unico cappello. Per esempio, se volessimo gestire le caratteristiche di un punto 2D su un piano cartesiano, l’approccio in C prevedeva un costrutto di questo tipo:
struct Punto2D {
double x;
double y;
};Una struttura come questa esprimeva semplicemente l’idea: abbiamo due variabili, x e y, entrambe di tipo double. In C++, però, lo stesso codice assume un significato leggermente più ampio. Infatti, il linguaggio ci consente di assegnare anche funzioni membro, costruttori, distruttori, operatori sovraccaricati e molto altro. In un certo senso, è come se le strutture fossero divenute quasi equivalenti alle classi, con la differenza principale che i membri di una struct sono pubblici per impostazione predefinita, mentre quelli di una classe lo sono solo se esplicitamente dichiarati tali.
È interessante notare come, nel tempo, le abitudini degli sviluppatori si siano evolute. C’è chi preferisce tenere le struct in un ruolo marginale, usandole soltanto per piccoli contenitori di dati, e chi invece le usa con disinvoltura come vere e proprie classi, soprattutto quando il contesto richiede un approccio più snello o quando si vuole evidenziare che l’elemento di cui si parla è “principalmente” un insieme di dati, pur includendo un minimo di logica. Non esiste una regola universale: è più una questione di stile e di convenzioni adottate dal team di lavoro.
Un approccio pratico all’utilizzo delle struct
Per capire come funziona una struct in C++ e come possano entrare in gioco i campi funzione, possiamo partire da un esempio un po’ più elaborato. Immaginiamo di voler gestire un piccolo record di informazioni su un libro, includendo il titolo, l’autore e l’anno di pubblicazione. In passato, ci saremmo limitati a scrivere qualcosa di simile:
struct Libro {
std::string titolo;
std::string autore;
int anno;
};
Fin qui, nulla di strano. Abbiamo tre campi, tutti pubblici per impostazione predefinita, e possiamo istanziare la nostra struct in modo molto semplice:
Libro libro1;
libro1.titolo = "Il giro del mondo in 80 giorni";
libro1.autore = "Jules Verne";
libro1.anno = 1873;Tuttavia, in C++ possiamo decidere di aggiungere una funzione membro che ci aiuti, per esempio, a stampare i dati del libro su schermo. Ecco che entrano in gioco i “campi funzione”, vale a dire metodi che vivono all’interno della struttura stessa:
struct Libro {
std::string titolo;
std::string autore;
int anno;
void stampaInfo() {
std::cout << "Titolo: " << titolo << std::endl;
std::cout << "Autore: " << autore << std::endl;
std::cout << "Anno: " << anno << std::endl;
}
};Osservando questo frammento di codice, ci rendiamo conto di quanto le struct abbiano guadagnato potere espressivo nel corso della storia di C++. Non stiamo più parlando di un semplice raggruppamento di variabili, bensì di un tipo di dato in grado di contenere anche funzioni che manipolano o restituiscono le informazioni interne. È vero che non è certo obbligatorio usare le struct in questa forma, ma è altrettanto vero che poterlo fare ci apre diverse possibilità. In questo modo, l’uso delle struct diventa una scelta naturale ogni volta che la priorità è raggruppare dati che sono correlati fra loro, rendendoli disponibili a un insieme di operazioni specifiche.
Campi funzione e logica interna
Le funzioni che risiedono all’interno di una struct non si limitano all’invio di messaggi su schermo. Possiamo definire operatori (come l’operatore di assegnazione, o l’operatore di confronto), possiamo inserire metodi di utilità per aggiornare i dati in maniera controllata, oppure per svolgere operazioni di calcolo. In breve, tutto ciò che faremmo con una classe è concesso anche a una struct, tenendo sempre a mente che la differenza di default sta nella visibilità dei membri.
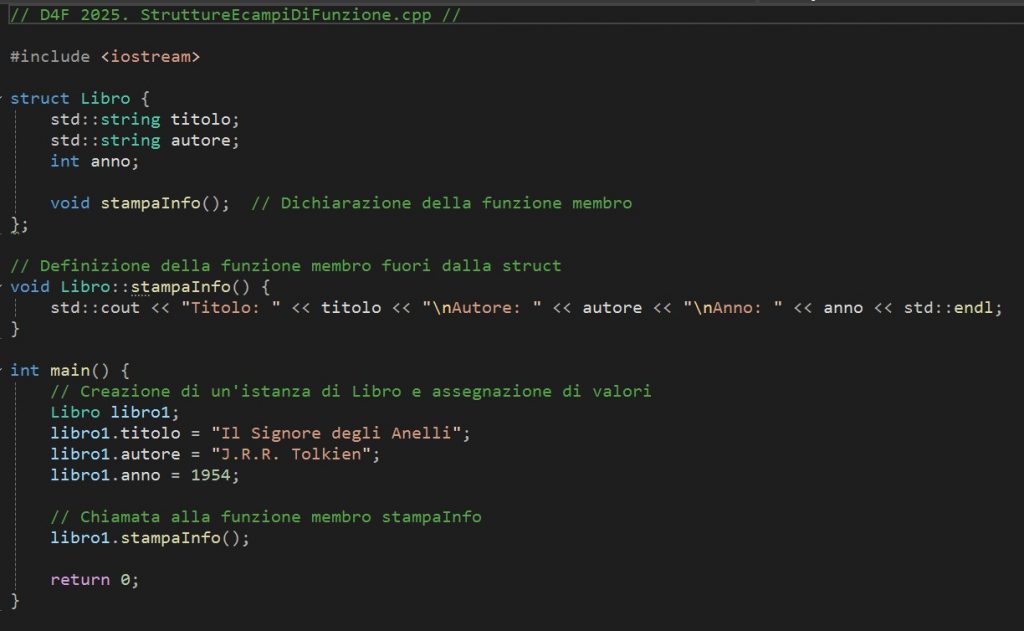
Le cosiddette “funzioni membro” (a cui ci riferiamo come “campi funzione” in questo articolo) possono anche essere dichiarate e definite al di fuori della struct stessa, tramite la notazione con l’operatore di risoluzione dello scope (::). È un approccio identico a quello che si usa con le classi. Se, per motivi di leggibilità, preferiamo tenere separato l’header (o la parte di dichiarazione) dalla definizione vera e propria, possiamo farlo in tutta tranquillità. Per esempio:
struct Libro {
std::string titolo;
std::string autore;
int anno;
void stampaInfo(); // Dichiarazione della funzione membro
};
// Definizione al di fuori della struct
void Libro::stampaInfo() {
std::cout << "Titolo: " << titolo << "\nAutore: " << autore << "\nAnno: " << anno << std::endl;
}
La logica rimane la stessa: le funzioni membro possono accedere ai dati interni senza dover ricorrere a parametri esterni, perché agiscono su this, ossia sul puntatore implicito all’istanza corrente della struct (o della classe). La sintassi è perfettamente sovrapponibile a quella delle classi, e questo rende le struct particolarmente versatili.
Vantaggi e differenze rispetto alle classi
È impossibile parlare di strutture in C++ senza mettere a confronto le loro caratteristiche con quelle delle classi, dato che, al giorno d’oggi, le due entità sono quasi equivalenti. In che modo si possono distinguere? Come già accennato, il punto chiave è che i membri di una struct sono pubblici di default, mentre quelli di una classe sono privati. Basta però una parola chiave (public:, private: o protected:) per cambiare il grado di accesso ai vari membri. Ne consegue che, tecnicamente, potremmo ottenere lo stesso identico risultato sia usando la parola chiave class sia usando la parola chiave struct. Questo rende la scelta fra i due termini, talvolta, quasi filosofica o stilistica.
Ci sono sviluppatori che preferiscono usare struct solo per i “plain old data” (spesso abbreviati in POD), ovvero oggetti che racchiudono un insieme di variabili senza alcuna particolare logica. Altri, invece, amano sfruttare i campi funzione anche all’interno di una struct, purché le responsabilità di quell’oggetto rimangano semplici e chiaramente incentrate sui dati. Da questo punto di vista, la differenza fra struct e class diventa più che altro un modo per comunicare al lettore del codice l’intenzione progettuale. Leggere struct fa subito pensare a un contenitore di dati piuttosto semplice, mentre class trasmette l’idea di un’entità più complessa, con incapsulamento di attributi e funzioni di vario tipo. È una sottile convenzione, ma spesso aiuta a mantenere il codice coerente e immediatamente comprensibile.
Uso di costruttori nelle strutture
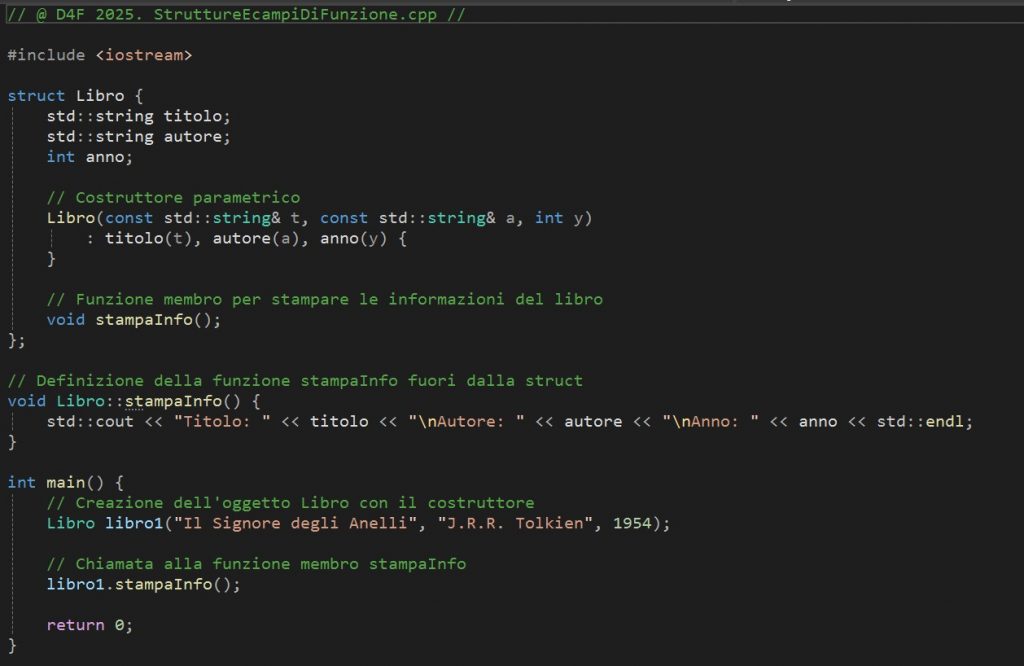
La possibilità di inserire funzioni membro in una struct si estende anche ai costruttori. In questo senso, una struct può essere dotata di un costruttore predefinito, di un costruttore parametrico e persino di costruttori di copia e di spostamento. Immaginiamo di voler creare un costruttore per la nostra struct Libro, in modo da semplificare l’inizializzazione dei dati:
struct Libro {
std::string titolo;
std::string autore;
int anno;
// Costruttore parametrico
Libro(const std::string& t, const std::string& a, int y)
: titolo(t), autore(a), anno(y) {}
};In questo modo, ogni volta che istanziamo la struct, possiamo farlo specificando i valori:
Libro libro2("1984", "George Orwell", 1949);Risulta evidente come la struct diventi un piccolo oggetto in grado di conservare i propri dati e di essere configurato già al momento della creazione, senza dover passare per l’assegnazione dei campi dopo l’istanza. Ancora una volta, ci troviamo in una situazione molto simile a quella delle classi, con l’unica eccezione che non abbiamo imposto alcuna regola di incapsulamento. Naturalmente, se volessimo, potremmo dichiarare i campi come privati e fornire soltanto l’accesso tramite metodi pubblici, proprio come faremmo con una classe. La flessibilità è totale.
Inserire distruttori e funzioni speciali
Una struct può anche includere un distruttore, un costruttore di copia e un costruttore di spostamento, esattamente come una classe. Queste funzioni speciali servono a controllare la gestione delle risorse, soprattutto quando si fa uso di memoria dinamica o di risorse di sistema (file, socket, ecc.). Per esempio, se avessimo bisogno di allentare manualmente una risorsa prima che l’oggetto venga distrutto, potremmo inserire un distruttore all’interno della struct e scrivere la logica necessaria.
La sintassi sarebbe analoga a quella di una classe. Se avessimo, per ipotesi, una struct che gestisce un buffer di memoria in modo grezzo, potremmo definire:
struct GestoreBuffer {
char* buffer;
std::size_t size;
GestoreBuffer(std::size_t s) : size(s) {
buffer = new char[s];
}
// Distruttore
~GestoreBuffer() {
delete[] buffer;
}
};È evidente quanto le struct in C++ possano ricoprire un ruolo molto più ampio rispetto a quanto ci si potrebbe aspettare dal classico uso di un costrutto di tipo “C”.
Quando i campi funzione fanno la differenza
A volte si tende a pensare che una struct debba rimanere un semplice blocco di dati, ma ci sono casi in cui le funzioni membro possono rendere il codice più elegante, più leggibile e più sicuro. Un esempio potrebbe essere quello di un vettore 2D, dove vogliamo effettuare calcoli matematici, come la somma con un altro vettore, la sottrazione o il calcolo della norma. Sfruttare i campi funzione ci permette di scrivere queste operazioni in modo naturale, proprio perché il codice viene tenuto “vicino” ai dati che manipola.
struct Vettore2D {
double x;
double y;
Vettore2D() : x(0), y(0) {}
Vettore2D(double nx, double ny) : x(nx), y(ny) {}
// Metodo per sommare due Vettori 2D
Vettore2D somma(const Vettore2D& altro) const {
return Vettore2D(x + altro.x, y + altro.y);
}
// Metodo per calcolare la norma
double norma() const {
return std::sqrt(x*x + y*y);
}
};
In questo modo, chi utilizza Vettore2D può concentrarsi più sulla logica matematica che sulle singole operazioni di accesso ai dati interni. La struct si comporta come un mini-modulo di calcolo, incapsulando dettagli di implementazione che altrimenti andrebbero disseminati in giro per il codice. Certo, potremmo ottenere lo stesso risultato con una classe, ma il concetto è che anche una struct svolge pienamente questo ruolo, con in più l’indicazione “implicita” che i dati interni non sono necessariamente nascosti al mondo esterno (a meno che non decidiamo di renderli privati).
Stile di programmazione e convenzioni
Nel corso degli anni, diverse community di sviluppatori hanno stabilito convenzioni su come utilizzare al meglio le struct. Alcuni suggeriscono di usare le struct soltanto quando i campi sono tutti pubblici e non ci sono funzioni che vanno a modificarli in modo articolato, riservando le classi per tutto ciò che richiede astrazione, incapsulamento e polimorfismo. Altri sviluppatori, invece, non vedono una netta distinzione e valutano di volta in volta quale parola chiave utilizzare in base all’uso previsto e alla semplicità del tipo di dato che stanno definendo.
Anche l’approccio alla documentazione e ai commenti può cambiare. In alcuni contesti, si preferisce specificare con precisione se una struct è pensata per rappresentare un semplice contenitore di dati o se invece include funzionalità significative. Il lettore di un codice ben documentato non si troverà mai spiazzato: comprenderà rapidamente se un certo blocco di codice è solo un pacchetto di variabili oppure un vero e proprio oggetto dotato di metodi utili.
Esempio: una semplice applicazione console
Proviamo a costruire un mini esempio completo, che metta insieme i concetti di strutture, campi funzione e costruttori. Immaginiamo di voler creare un piccolo programma console che gestisca un inventario di prodotti, ciascuno caratterizzato da un nome, un prezzo e una quantità in stock. Definiremo una struct chiamata Prodotto, che includerà un costruttore e una funzione per stampare le informazioni sul prodotto. Poi creeremo un breve frammento di codice che mostri come potrebbe avvenire l’uso di questa struct.
#include <iostream>
#include <string>
#include <vector>
struct Prodotto {
std::string nome;
double prezzo;
int quantita;
// Costruttore parametrico
Prodotto(const std::string& n, double p, int q)
: nome(n), prezzo(p), quantita(q) {}
// Funzione membro per stampare le info del prodotto
void stampaDettagli() const {
std::cout << "Nome: " << nome << "\n";
std::cout << "Prezzo: " << prezzo << "\n";
std::cout << "Quantità: " << quantita << "\n\n";
}
// Metodo per calcolare il valore totale in magazzino
double valoreTotale() const {
return prezzo * quantita;
}
};
int main() {
std::vector<Prodotto> magazzino;
magazzino.emplace_back("Mela", 0.5, 100);
magazzino.emplace_back("Banana", 0.3, 200);
magazzino.emplace_back("Arancia", 0.4, 150);
double valoreComplessivo = 0.0;
for(const auto& prodotto : magazzino) {
prodotto.stampaDettagli();
valoreComplessivo += prodotto.valoreTotale();
}
std::cout << "Valore complessivo del magazzino: " << valoreComplessivo << std::endl;
return 0;
}Nel blocco di codice presentato, si notano alcuni aspetti importanti. La struct Prodotto ha campi pubblici, un costruttore che inizializza i campi e due funzioni membro: una per stampare i dettagli e una per calcolare il valore totale del prodotto in base al suo prezzo e alla quantità. Il main si limita a creare una serie di prodotti, memorizzarli in un vettore e iterare su di essi, sfruttando i metodi che la struct mette a disposizione. È un esempio basico, ma già racchiude l’idea chiave: possiamo manipolare dati e logica in un unico costrutto, senza dover necessariamente ricorrere a una classe.
Struct e funzioni friend
Non bisogna dimenticare che le struct, come le classi, permettono di dichiarare funzioni e classi “amiche” (friend). Si tratta di un meccanismo che consente l’accesso ai membri privati o protetti da parte di entità esterne, sebbene ciò debba essere usato con cautela. Dichiarare una funzione friend in una struct significa che quella funzione potrà accedere ai dati privati della struct, cosa che in assenza di friend sarebbe vietata. Nella pratica quotidiana, l’uso delle funzioni friend tende a rimanere un po’ più raro rispetto al passato, perché spesso si preferisce un approccio più modulare e incapsulato, ma è giusto sapere che la possibilità esiste.
Altri aspetti: membri statici, const, mutable e volatile
Se volessimo, potremmo approfondire anche l’uso di membri statici all’interno delle struct. Un membro statico è uno spazio di memoria o una funzione che appartiene a tutta la struct in generale, non a una singola istanza. Ciò può risultare utile quando si vuole conservare un contatore globale o quando una certa funzione non dipende dai dati di una singola istanza.
La parola chiave const si applica, come nel caso delle classi, a metodi che non modificano lo stato interno dell’oggetto. In un metodo dichiarato const, non è possibile cambiare i valori dei campi, a meno che questi non siano dichiarati mutable, un aggettivo che consente di alterare il valore di un determinato membro anche nei metodi const. Questa caratteristica può essere utilizzata, ad esempio, per un contatore di debug o per altri scopi in cui vogliamo mantenere la facciata immutabile, ma avere comunque la libertà di aggiornare una certa informazione di servizio.
Il keyword volatile è un altro aspetto avanzato, utilizzato soprattutto in contesti di programmazione concorrente o di basso livello, dove alcuni dati potrebbero essere modificati inaspettatamente da eventi esterni. Dichiarare una variabile volatile dice al compilatore di non ottimizzare in modo aggressivo l’accesso a quel campo, perché il suo contenuto potrebbe cambiare al di fuori del flusso di esecuzione attuale.
Tutti questi concetti si applicano in egual misura a struct e class, a dimostrazione del fatto che, dal punto di vista del linguaggio, la distinzione è molto sottile.
Integrazione con altri paradigmi
Nell’ecosistema C++ moderno, si sta dando sempre più spazio a paradigmi e stili di programmazione che sfruttano template, lambda, programmazione funzionale e design pattern ben collaudati. Le struct non sono escluse da questo sviluppo, anzi, spesso sono proprio la soluzione più agile quando si tratta di creare oggetti semplici da passare a funzioni template o quando si deve definire un tipo leggero, senza troppa cerimonia.
In alcune librerie si notano pattern ricorrenti che fanno uso di struct come accumulatori di parametri, soprattutto in quei casi in cui una funzione richiede molte informazioni. Una struct funge da raccoglitore di input, che poi viene passato all’algoritmo o alla libreria di turno. Questo approccio è utile per evitare liste di parametri molto lunghe e per gestire con ordine i valori di configurazione.
Considerazioni sulle performance
Sul piano delle performance, non c’è una differenza rilevante fra struct e class, se paragonate a parità di contenuto e di utilizzo. Il compilatore non tratta la parola chiave struct in modo diverso da class sotto il profilo dell’ottimizzazione. Naturalmente, le prestazioni dipendono dall’organizzazione dei dati, dalla presenza di eventuali metodi virtuali, dalla presenza di eredità e da altre considerazioni tipiche di C++.
In generale, creare una struct ben definita con campi funzione essenziali non introduce overhead particolari. Anzi, un codice ben strutturato potrebbe risultare più facile da ottimizzare per il compilatore, perché si riducono gli errori logici, le duplicazioni di codice e gli effetti collaterali. Dunque, l’uso delle struct non va temuto né etichettato come meno efficiente rispetto alle classi. La vera discriminante, come quasi sempre accade, è l’architettura generale del programma e le scelte di design che si fanno nel corso dello sviluppo.
Arrivati a questo punto, si può affermare con tranquillità che le strutture in C++ rappresentano uno strumento potente e flessibile, in grado di evolversi da semplici contenitori di dati a entità che includono funzioni, costruttori e persino distruttori. L’idea dei “campi funzione” all’interno di una struct testimonia come il linguaggio si sia emancipato dalla sua eredità puramente procedurale, offrendo ai programmatori la possibilità di adottare un approccio molto più orientato agli oggetti anche con costrutti che nascono in un contesto di C.
Non bisogna cadere nell’errore di credere che le struct siano soltanto un lascito di tempi andati. In molti progetti moderni, specialmente quelli in cui si desidera una chiara separazione fra dati e funzioni, o dove l’overhead concettuale di una classe non viene ritenuto necessario, le struct continuano a giocare un ruolo di primo piano. I campi funzione, dal canto loro, sono uno strumento eccezionale per mantenere le operazioni di base ben vicine ai dati di cui si occupano, senza costringere lo sviluppatore a creare interfacce esterne o funzioni amiche.
Guardando al futuro, il C++ continua a evolvere, ma le strutture rimangono un pilastro inamovibile della sintassi e della semantica del linguaggio. Che si voglia programmare in modo più procedurale o più orientato agli oggetti, le struct forniscono un ponte naturale fra i due mondi, regalando al programmatore un ventaglio di possibilità che spaziano dalla semplice aggregazione di variabili a vere e proprie mini-classi. Inserire funzioni membro – i cosiddetti campi funzione – non fa altro che valorizzare questo costrutto, rendendolo un alleato prezioso ogni volta che si desidera definire un tipo di dato completo, dotato di comportamenti specifici, ma non eccessivamente sofisticato da richiedere l’intero armamentario di una classe con incapsulamento forzato.
In definitiva, il suggerimento è quello di non sottovalutare le potenzialità delle struct e di non limitarsi a considerarle mero retaggio del C. Se la scelta fra struct e class può sembrare dettata dall’abitudine o da una sottile convenzione, è opportuno ricordare che la reale differenza sta nel modo in cui si sceglie di impiegare questi costrutti. Se l’obiettivo è rappresentare un insieme di dati, gestirlo con semplicità, e aggiungere un pizzico di logica per semplificare la vita allo sviluppatore, allora le struct con campi funzione sono una scelta di grande efficacia. Le classi, a loro volta, rimangono irrinunciabili quando il livello di astrazione e incapsulamento diventa elevato, oppure quando entra in gioco l’ereditarietà e il polimorfismo.
Eppure, ogni regola è fatta per essere interpretata in funzione del contesto: per certi versi, la differenza fra struct e class in C++ è più nella testa del programmatore che nel compilatore. Imparare a maneggiare con disinvoltura entrambi i costrutti, comprendendone appieno analogie e differenze, è un tassello fondamentale per chiunque desideri scrivere codice C++ moderno, pulito e robusto. E a volte, il modo migliore di imparare è proprio quello di sperimentare: prendere una struct, aggiungere un paio di funzioni membro e osservarne il comportamento all’interno di un piccolo progetto, così da capire fin dove ci si può spingere e come questo approccio possa rendere il codice più armonioso.
In conclusione, “Strutture e campi funzione” in C++ non è solo un binomio tecnico, ma un vero e proprio simbolo dell’evoluzione del linguaggio. È la dimostrazione che, in una realtà fatta di continui cambiamenti, perfino un costrutto nato per scopi essenzialmente procedurali possa trasformarsi in uno strumento di programmazione a oggetti completo, senza rinunciare a quella semplicità di base che lo ha reso tanto diffuso e apprezzato. Saperlo utilizzare con astuzia significa avere a disposizione uno strumento in più per scrivere codice espressivo, flessibile e facile da mantenere. Un traguardo che ogni appassionato di C++ – principiante o esperto che sia – può decidere di far proprio, esplorando tutte le potenzialità che un linguaggio così ricco è in grado di offrire.
3 Commenti
Tutte le lezioni precedenti sono caricate di contenuto, arrivata a questa e le successive risultano tutte cosi :
” Il contenuto della lezione è vuoto.”.
Non è presente ne video, ne testo, appunto è vuoto. Ma come mai? ho pagato il corso, non mi aspettavo di trovare parte del corso vuoto. Si può risolvere?
Ciao Gaetano,
ti ringrazio per aver segnalato il problema e mi dispiace per l’inconveniente. Purtroppo, a causa di un errore tecnico, alcune lezioni erano state pubblicate prima che venissero completate, risultando così “vuote”. Abbiamo già provveduto a inserire il contenuto previsto per quelle lezioni e, a breve, arricchiremo ulteriormente il corso con nuovi materiali.
Se dovessi incontrare altre difficoltà o avere ulteriori domande, non esitare a contattarci. Grazie per la pazienza e per il tuo interesse nel corso!
Grazie mille Antonella, gentilissima. Mi sta piacendo molto il corso! proseguirò nelle lezioni del corso trepidante dell’attesa di possibili implementi di materiale testo/video 🙂